The Resume-Driven Architecture in Data Engineering
Resume-Driven Architecture is a common issue across many areas of software engineering, and data engineering is no exception. In this post, I’ll share my thoughts on what this problem is, why it persists, and how it continues to affect the industry. Although you may be already understand my opinion by the view of the cover image, I will try to elaborate more.
The What
Resume-Driven Architecture refers to decision-making in system design that is driven more by personal ambition or trendy technologies than by actual business needs. In other words, developers build systems with tools or architectures that might be suitable for Netflix or Facebook but are entirely overkill for, say, a small manufacturing unit.
The result? Over-engineered solutions for problems that don’t exist. This is problematic for both individuals and the industry.
For individual data engineers, myself included, it's easy to fall into this trap. We become so focused on mastering shiny new tools that we lose sight of the bigger picture. Specialization is not inherently bad, but to grow into senior roles, it’s essential to develop perspective. Understanding which tools are appropriate for which problems becomes far more valuable than simply knowing the tools inside and out.
From an industry perspective, resume-driven architectures can prevent companies from becoming data-driven. Building and maintaining complex data infrastructures is costly—too costly for many smaller businesses. Larger organizations end up spending enormous amounts of money on trivial tasks, only because they’re using tools ill-suited to their actual needs.
Take Spark, for example. Today, it seems like everyone is using Spark for their ETL workloads, even though most companies don’t truly have big data. And of those that do, very few are even querying it regularly. Jordan Tigani from motherduck shared a blog post on the topic with name “Redshift Files: the Hunt for Big Data”. Based on data published by the AWS itself, he shows that almost no one uses Big Data at its data warehouse. So, my question is why almost all the organizations need a Big Data processing framework such as Spark. While Resume-Driven Architecture isn’t the only reason for this widespread Spark adoption, it certainly plays a significant role.
The Why
Why does this keep happening? The reasons are complex, but I have a few ideas.
Admiration for Big Tech: Many developers look to companies like Google, Facebook, and Netflix as the gold standard. There’s a strong temptation to use the same tools and architecture patterns, hoping it proves we’re capable of working at that level.
Startups and Solution Marketing: Some startups become successful by solving problems specific to large enterprises. However, they often market their solutions to everyone, whether or not those customers share the same challenges. This drives widespread adoption of solutions designed for problems most companies don’t actually face.
Reproduction of Developers: There’s also a self-reinforcing loop at play. Developers who don’t see the problem become part of the problem. They build teams of like-minded individuals, further perpetuating the trend. These developers can be highly skilled, but if they don’t recognize when tools are being misapplied, they contribute to the cycle.
The How
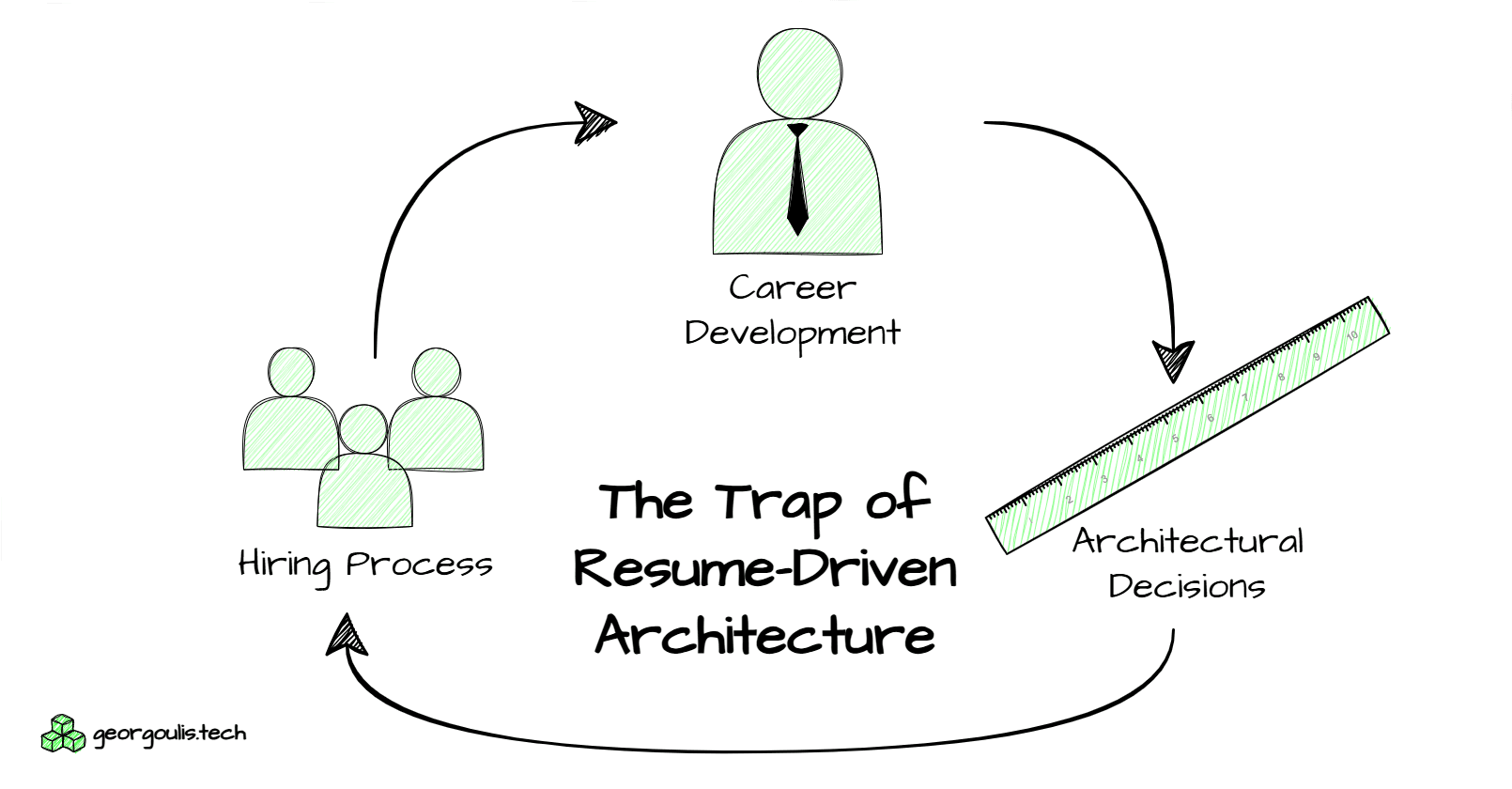
The cycle of Resume-Driven Architecture is fueled by a few key factors:
Hiring Processes: Hiring in data engineering is largely based on keywords. Resumes filled with buzzwords like "Kafka," "Hadoop," and "PySpark" tend to pass the first filter. The problem is that hiring managers often don’t have the technical expertise to evaluate candidates properly, so the process becomes biased toward those who’ve worked with trendy technologies, regardless of whether those tools are appropriate for the role.
Architectural Decision-Making: Often, developers who themselves are focused on resume-building make the key architectural decisions. This leads to teams built with the same mindset, reinforcing the preference for trendy, resume-boosting tools. Job descriptions then reflect this bias, filtering for individuals who are familiar with those same technologies.
Misguided Career Development: Finally, developers entering the job market often feel pressure to match these expectations. Overwhelmed by enthusiasm for the latest tech, they begin molding their skill sets to align with these trends, even if those trends don't align with the problems they’ll actually need to solve.

Breaking the Cycle
So, how do we break free from this loop of Resume-Driven Architecture? It starts with focusing on fundamentals. We need to start from the problem we are facing, and describe the specification of the solution that could solve the problem we confront. Then we can move forward to the tool selection. And when we have a few options in mind we need to consider:
Do we really need this solution?
Does this tool add value to the business, or are we using it just because it’s trendy?
Hiring processes must also evolve. Instead of filtering candidates by trendy keywords, recruiters and technical leads should focus on problem-solving abilities and context-awareness—skills that are crucial for deciding when and where to apply specific technologies. Similarly, developers need to recognize the difference between skill-building for personal growth and implementing solutions that actually benefit the company.
Ultimately, it's about balance. It’s great to be a specialist, but to thrive in senior roles and build long-lasting solutions, we must broaden our perspective. Not every company needs to operate like Netflix, and not every problem requires a cutting-edge tool to solve. Sometimes, simple and pragmatic solutions are not just sufficient—they’re the most effective.
Conclusion
Resume-Driven Architecture is a pervasive issue in data engineering, and it’s not going away anytime soon. However, by becoming more aware of the problem, we can begin to shift our mindset. Let’s aim to build architectures that solve real business problems, not just pad our resumes.